Batch convert multiple web pages, html files or images into one e-book.

Project description
xml2epub







Batch convert multiple web pages, html files or images into one e-book.
Features:
- Automatically generate cover: If the
<title>text in html is one of COVER_TITLE_LIST, then the cover will be added automatically, otherwise the default cover will be generated. We will randomly generate the cover image with a similar "O'Reilly" style. - Automatically obtain the core content of the article: we filter the obtained html string and retain the core content. See SUPPORTED_TAGS for a list of tags reserved in html.
ToC
How to install
xml2epub is available on pypi
https://pypi.org/project/xml2epub/
$ pip install xml2epub
Basic Usage
import xml2epub
## create an empty eBook
book = xml2epub.Epub("My New E-book Name")
## create chapters by url
#### custom your own cover image
chapter0 = xml2epub.create_chapter_from_string("https://cdn.jsdelivr.net/gh/dfface/img0@master/2022/02-10-0R7kll.png", title='cover', strict=False)
#### create chapter objects
chapter1 = xml2epub.create_chapter_from_url("https://dev.to/devteam/top-7-featured-dev-posts-from-the-past-week-h6h")
chapter2 = xml2epub.create_chapter_from_url("https://dev.to/ks1912/getting-started-with-docker-34g6")
## add chapters to your eBook
book.add_chapter(chapter0)
book.add_chapter(chapter1)
book.add_chapter(chapter2)
## generate epub file
book.create_epub("Your Output Directory")
After waiting for a while, if no error is reported, the following "My New E-book Name.epub" file will be generated in "Your Output Directory":
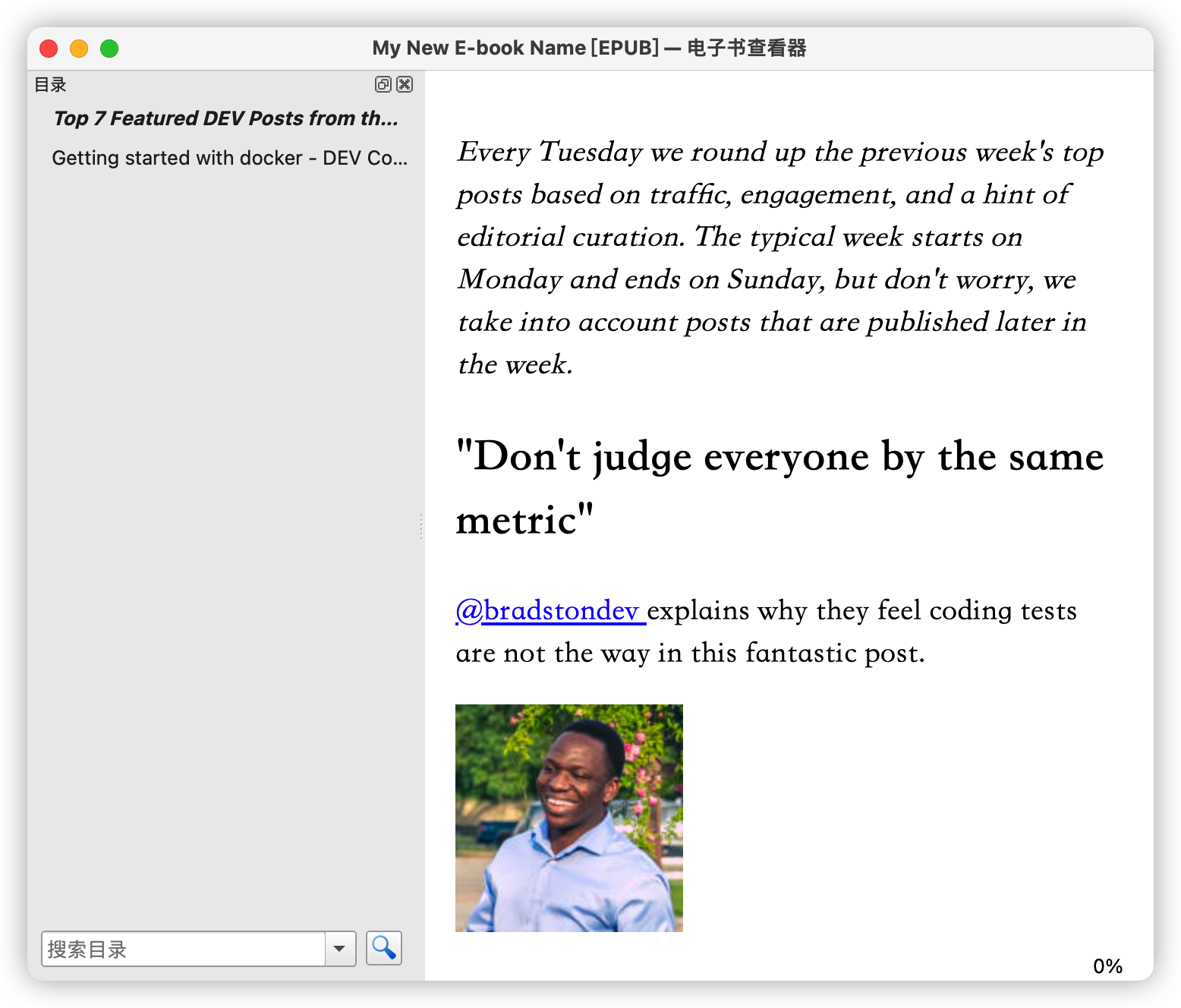
For more examples, see: examples directory.
If we cannot infer the cover image from html string, we will generate one. The randomly generated cover image is a similar "O'Reilly" style:

API
create_chapter_from_file(file_name, url=None, title=None, strict=True, local=False): Create a Chapter object from an html or xhtml file.- file_name (string): The filename containing the html or xhtml content of the created chapter.
- url (Option[string]): The url used to infer the chapter title. It is recommended to bring the
urlparameter, which helps to identify relative links in the web page. - title (Option[string]): The chapter name of the chapter, if None, the content of the title tag obtained from the web file will be used as the chapter name.
- strict (Option[boolean]): Whether to perform strict page cleaning, which will remove inline styles, insignificant attributes, etc., generally True.
- local (Option[boolean]): Whether to use local resources, which means that all images and css files in html have been saved locally, and the resources will be copied directly using the file path in html instead of getting them from the Internet.
create_chapter_from_url(url, title=None, strict=True, local=False): Create a Chapter object by extracting webpage from given url.- url (string): website link. It is recommended to bring the
urlparameter, which helps to identify relative links in the web page. - title (Option[string]): The chapter name of the chapter, if None, the content of the title tag obtained from the web file will be used as the chapter name.
- strict (Option[boolean]): Whether to perform strict page cleaning, which will remove inline styles, insignificant attributes, etc., generally True. When False, you can enter an image link and specify title, which is helpful for custom cover image.
- local (Option[boolean]): Whether to use local resources, which means that all images and css files in html have been saved locally, and the resources will be copied directly using the file path in html instead of getting them from the Internet.
- url (string): website link. It is recommended to bring the
create_chapter_from_string(html_string, url=None, title=None, strict=True, local=False): Create a Chapter object from a string. The principle of the above two methods is to first obtain the html or xml string, and then call this method.- html_string (string): html or xhtml string or image url (with
strict=False) or image path (withstrict=Falseandlocal=True). When it is an image, if there is notitlefield or thetitlefield is any one ofCOVER_TITLE_LIST, such ascover, then the image will be used as the cover. - url (Option[string]): The url used to infer the chapter title. It is recommended to bring the
urlparameter, which helps to identify relative links in the web page. - title (Option[string]): The chapter name of the chapter, if None, the content of the title tag obtained from the web file will be used as the chapter name.
- strict (Option[boolean]): Whether to perform strict page cleaning, which will remove inline styles, insignificant attributes, etc., generally True.
- local (Option[boolean]): Whether to use local resources, which means that all images and css files in html have been saved locally, and the resources will be copied directly using the file path in html instead of getting them from the Internet.
- html_string (string): html or xhtml string or image url (with
Epub(title, creator='dfface', language='en', rights='', publisher='dfface', epub_dir=None): Constructor method to create Epub object.Mainly used to add book information and all chapters and generate epub file.- title (str): The title of the epub.
- creator (Option[str]): The author of the epub.
- language (Option[str]): The language of the epub.
- rights (Option[str]): The copyright of the epub.
- publisher (Option[str]): The publisher of the epub.
- epub_dir(Option[str]): The path of intermediate file, the system's temporary file path is used by default, or you can specify it yourself.
- Epub object
add_chapter(chapter_object): Add Chapter object to Epub.- chapter_object (Chapter object): Use the three methods of creating a chapter object to get the object.
- Epub object
create_epub(output_directory, epub_name=None): Create an epub file from the Epub object.- output_directory (str): Directory to output the epub file to.
- epub_name (Option[str]): The file name of your epub. Each character of the file name must be printable and pass the
str.isprintable()test. Unprintable characters will be filtered. This should not contain .epub at the end. If this argument is not provided, defaults to the title of the epub. - absolute_location (Option[str]): The absolute path and file name of the file, excluding the file type suffix (do not contain .epub at the end). If not passed, the file location is
${current working path}/${output_directory}/${epub_name}.epub. If this parameter is passed, the file will be saved at the absolute path specified by the parameter. Please make sure you have write permission to the location and the path is legal.
html_clean(input_string, help_url=None, tag_clean_list=constants.TAG_DELETE_LIST, class_list=constants.CLASS_INCLUDE_LIST, tag_dictionary=constants.SUPPORTED_TAGS): The internal defaultcleanmethod we expose for easy customization.- input_string (str): A string representing HTML / XML.
- help_url (Option[str]): current chapter's url, which helps to identify relative links in the web page.
- tag_dictionary (Option[dict]): defines all tags and their classes that need to be saved, you can see what the default values are in SUPPORTED_TAGS.
- tag_clean_list (Option[list]): defines all tags that need to be deleted. Note that the entire tag and its sub-tags will be deleted directly here. You can see what the default values are in TAG_DELETE_LIST.
- class_list (Option[list]): defines all tags containing the content of the class that need to be deleted, that is, as long as the class attribute of any tag contains the content in this list, then the entire tag will be deleted including its sub-tags. You can see what the default values are in CLASS_INCLUDE_LIST.
Tips
- If you want to add a cover image yourself, use the
create_chapter_from_stringmethod, then assignhtml_stringto the image URL (e.g.https://www.xxx.com/xxx.png) and keep thestrict=Falseparameter. Or assignhtml_stringto the local image file path (e.g../xxx.png) and keep thelocal=Trueandstrict=Falseparameters. And it's better to add atitle='Cover'parameter. - If you want to clean the web content yourself, first use the crawler to get the html string, then use the exposed
html_cleanmethod (it is recommended to add the values oftag_clean_list,class_clean_listandurl) and assign the output to thecreate_chapter_from_stringmethodhtml_stringparameter while keepingstrict=False. - No matter which method, when using
create_chapter_*andstrict=False, it is recommended to bring theurlparameter, which helps to identify relative links in the web page. - Whenever you use the
html_cleanmethod, it is recommended to include thehelp_urlparameter, which helps to identify relative links in web pages. - After generating the epub, it is better to use calibre to convert the
epubto a more standards-compliantepub/mobi/azw3to solve the problem that the epub cannot be read in some software. And if the generated epub has style problems, you can also use calibre to edit the ebook and adjust the style to suit your reading habits. - If the images and CSS files in your html are local resources, please set the
localparameter increate_chapter_*toTrue, then the program will automatically copy the local resources instead of getting them from the Internet.
FAQ
- The generated epub has no content?
When generating an epub by URL, you need to ensure that the web page corresponding to the URL is a static web page, and you can access all the content without logging in. If the epub you generate is empty when opened, then you may have encountered a website that requires login to access. At this time, you can try to obtain the html string corresponding to the URL, and then use the
create_chapter_from_stringmethod to generate the epub. That is to say, you need to use a certain crawler technology.
- The generated epub contains content I don't want?
Although we do some filtering when cleaning the html string, this is not guaranteed to work in all cases. In this case, I recommend that you filter the html string yourself before using
create_chapter_from_stringmethod.
- Want to generate epub directly from html string without sanitizing content?
Set the parameter
strictofcreate_chapter_from_stringtoFalse, which means that it will not be cleaned up internally.
- If you choose to get the html string yourself and clean it up yourself, you can follow these steps:
- Use crawler technology to obtain html strings, such as
requests.get(url).text. - Use the
html_cleanmethod we expose to clean up the string, e.g.html_clean(html_string, tag_clean_list=['sidebar']). Or you can write your own methods to sanitize strings, all just to get clean strings, whatever you want. - Using the
create_chapter_from_string(html_string, strict=False)method to generate the Chapter object, pay special attention to the parameterstrictto be set to False, which means that our internal cleaning strategy will be skipped. - After that, you can generate epub according to the basic usage. See vuepress2epub.py as an example.
- Use crawler technology to obtain html strings, such as
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







