Python package to download HPO annotations and mapping to Uniprot ID and AC and CAFA4 IDs.

Project description
hpo_downloader







Python package to download HPO annotations and mapping to Uniprot ID and AC and CAFA4 IDs.
How do I install this package?
As usual, just download it using pip:
pip install hpo_downloaderTests Coverage
Since some software handling coverages sometime get slightly different results, here’s three of them:



Pipeline
The package pipeline is illustrated in the following image:
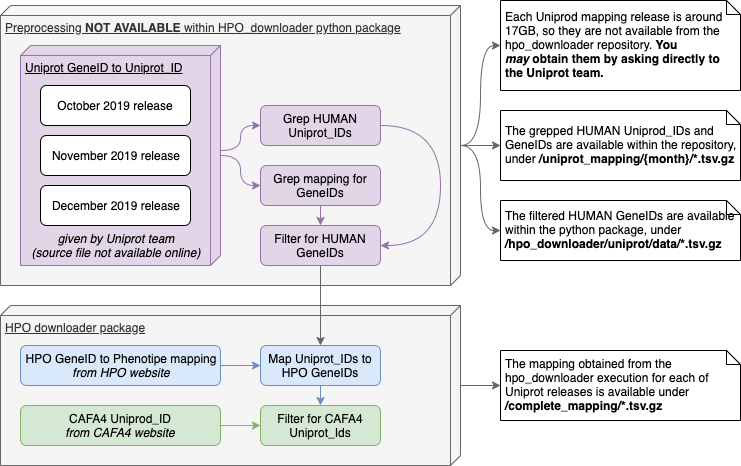
Preprocessing
For the pre-processing you have to retrieve the
uniprot mapping files by asking directly to the Uniprot team
since each mapping is aroung 17GB.
Let’s save each file in a directory within this repository called
"mapping/{month}/idmapping.dat.gz".
Cache for the pre-processing results is available within the python package, so there is no need to retrieve the original files unless you need to fully reproduce the pipeline.
For each release, we have to retrieve the "GeneID"
and the human uniprot_IDs, and we can do so using
zgrep.
zgrep "GeneID" mapping/{month}/idmapping.dat.gz > gene_id.tsv
zgrep "HUMAN" mapping/{month}/idmapping.dat.gz > human_id.tsvNow we have to map in a non-bijective way uniprot IDs
to GeneIDs on the uniprot ACs.
We can use the package method non_unique_mapping.
from hpo_downloader.utils import non_unique_mapping
import pandas as pd
gene_id = pd.read_csv(
f"mapping/{month}/gene_id.tsv",
sep="\t",
header=None,
usecols=[0, 2]
)
gene_id.columns = ["uniprot_ac", "gene_id"]
human_id = pd.read_csv(
f"mapping/{month}/human_ids.tsv",
sep="\t",
header=None,
usecols=[0, 2]
)
human_id.columns = ["uniprot_ac", "uniprot_id"]
non_unique_mapping(gene_id, human_id, "uniprot_ac").to_csv(
f"hpo_downloader/uniprot/data/{month}.tsv.gz",
sep="\t",
index=False
)Package usage examples
To generate the complete mapping (optionally filtering only for Uniprot IDs within CAFA4) proceed as follows:
from hpo_downloader import mapping
my_mapping = mapping(
month="november"
)
my_mapping_cafa_only = mapping(
month="november",
cafa_only=True
)The obtained pandas DataFrames look as follows:
HPO mappings: October, November, December
gene_id |
hpo_id |
uniprot_ac |
uniprot_id |
|---|---|---|---|
8192 |
HP:0004322 |
Q16740 |
CLPP_HUMAN |
8192 |
HP:0001250 |
Q16740 |
CLPP_HUMAN |
8192 |
HP:0000786 |
Q16740 |
CLPP_HUMAN |
8192 |
HP:0000007 |
Q16740 |
CLPP_HUMAN |
8192 |
HP:0000252 |
Q16740 |
CLPP_HUMAN |
HPO mappings (CAFA4 only): October (CAFA only), November (CAFA only), December (CAFA only)
cafa4_id |
uniprot_id |
gene_id |
hpo_id |
uniprot_ac |
|---|---|---|---|---|
T96060000002 |
1433E_HUMAN |
7531 |
HP:0000960 |
P62258 |
T96060000002 |
1433E_HUMAN |
7531 |
HP:0001539 |
P62258 |
T96060000002 |
1433E_HUMAN |
7531 |
HP:0002119 |
P62258 |
T96060000002 |
1433E_HUMAN |
7531 |
HP:0002120 |
P62258 |
T96060000002 |
1433E_HUMAN |
7531 |
HP:0000463 |
P62258 |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







