Fermy is a toolkit to empower fermentation data analysis from Pandas DataFrame.

Project description

Fermy is a toolkit to empower fermentation data analysis independent of any SCADA. Input data have to be converted in Python Pandas DataFrame with datetime or deltatime converted into float as index. Fermy is composed of two sub-modules:
pandasfermy add to Pandas methods to compute specific analysis on fermentation data e.g. with growth rate and lagtime calculation with DataFrame.fermgrowth()
plotlyfermy add to Pandas methods to plot fermentation data with dedicated kinds of charts like Control Chart or Multi-Yaxis Chart e.g. DataFrame.fccplot().
Fermy also includes drivers for laboratory devices like scales (Sartorius Entris or Entris II), peristaltic pumps (Watson Marlow pump 120U connect to a computer through a Labjack T7) & Mettler Toledo sensor mount transmitter as new classes: PompWatMarlo, BalanceEntris, MTPReader & M80. To access to those drivers just make “import fermy.driverslabtool” and then “fermy.driverslabtool.pumps.<ClassName>” or “fermy.driverslabtool.scales.<ClassName>” or “fermy.driverslabtool.probes.<ClassName>”.
Fermy also includes “CINAC” like calculations from DataFrame with pH values in columns and time in minutes as float as index. To access to those tool just make “import fermy.CINAC” and then new methods are available DataFrame.cinac() & DataFrame.inter().
Fermy also includes support for Micro Titer Plate (MTP) like 96-well readers from many brands. To access to those function just make “import fermy.MTP”.
The project is hosted on https://gitlab.com/
To install it, please simply used “pip install fermy”
or to install it, and use laboratory hardware drivers used “pip install fermy[device]”
To use it, please simply make:
import fermy
and then use them as any other methods of Pandas:
DataFrame.<methodname>()
Methods from pandasfermy
- fermgrowth: Function to compute maximal growth rate and lagtime. It is based on a mix of two algorithms describes in Toussaint et al. 2006 and Hall et al. 2014.
Input: A DataFrame with only data considered as proxy of biomass can be used. DataFrame index has to be a float corresponding to a delta time (in hours) or pandas.DatetimeIndex
- Parameters:
usemax: allow users by use chose between normalization methods: average of the first five points (by default) or percentage of the maximal value of dataset
percentofmax: allow users to change the percentage of maximal value used
timethreshold: allow users to compute growth rate without considering data from time before the provided number of hours
deltathreshold: allow users to exclude data without a minimal Biomass proxy delta between min and max of the column
percentegra: allow users to change the % used to select the relevent slope area (EGRA) variation of max slope by default 95% (0.95) of max slope.
Output: return a DataFrame with lagtime and maximal growth rate
- fermmultiaux: Function to compute growths rates and lagtimes for multiauxies It is based on a mix of two algorithms describes in the following: Toussaint et al. 2006 and Hall et al. 2014. Whereas growth rates are found with local max computation.
Input: A DataFrame with only data considered as proxy of biomass can be used. DataFrame index has to be a float corresponding to a delta time (in hours) or pandas.DatetimeIndex
- Parameters:
usemax: allow users by use chose between normalization methods: average of the first five points or percentage of the maximal value of dataset
percentofmax: allow users to change the percentage of maximal value used
Output: return a DataFrame with lagtimes and growth rates
- multirename: Function to rename from a dictionary in forme {"newname" : (possibleoldname1, possibleoldname2)} and rename columns in a DataFrame like possiblename1 ==> new name.
Input: DataFrame, Dictionary with key as new column name and values list of values possibly used in the Dataframe as columns
Output: return a DataFrame with new columns names
- replicates(“SeparationCharacter”): Function to average data from a pandas DataFrame grouping by left part of column name after splitting it by a defined separated character (sepchar).
Input: DataFrame with columns name with pattern “commonpartSEPCHARuniqueid”, The character that separate base name to sample identification
Output: return a DataFrame with averaged data per base name
Methods from plotlyfermy
- fccplot: Function to compute and plot a simple (and pretty) Control Chart with Plotly express.
Input: Data will be values of the column named variableofinterest and index of the DataFrame as plot index
- Parameters:
path: is provided the graph will be saved in this location.
dicorename: allow users to custom names of axis with {“old name” : “desired name”}.
forcepower: allow users to force scientific notation 10^n for the y-axis and control limits.
addccviol: allow users to add a new column to original data with CC rules check-in.
colorby: allow users to color data help to one column values
outref: allow users to compute ULC, LCL and mean from given data (pd.Series)
hql: allow to plot high quality limit
lql: allow to plot low quality limit
overinfo: allow to request additional information on ccplot
Output: return a DataFrame like data with only Control Chart violations data
fplotsimple: Plot all columns of a Dataframe as Y and index for x with Plotly express
- fplotmultiy: Plot all columns of a Dataframe with autogenerated multi-y-axis and index for x.
Input: DataFrame
- Parameters:
path: is provided the graph will be saved in this location
yspace: allows users to custom space between yaxis
sizep: allows users to custom font size
groupby: used character to build group for plotting e.g. groupby=”-” for pH-Biroeactor1 => group pH and subdataset bioreactor1
xtitle: allows to custom x title (string is exptected)
Output: No output only graph
Usage and code demonstration
First we create fake datasets: fakedfcc for control chart and fakedfferm for fermentation
import numpy as np import pandas as pd import math # fake process follow-up data np.random.seed(2) datanorm = np.random.normal(size = 100, loc = 50) datanormpower = datanorm*10**5 datanorm[51] = 56 # add uggly data fakedfcc = pd.DataFrame(data={"num" : datanorm, "numpower" : datanormpower}, columns=["num", "numpower"]) # fake fermentation data time = [time/60 for time in range(0, 60*6, 5)] # time 5 minutes steps in hours for 6 hours pH1 = np.random.normal(size=len(time),loc=6.5,scale=0.005) pH2 = np.random.normal(size=len(time),loc=7.2,scale=0.005) lagtime = time[20] # 1.66 h biomass1 = [0.5]*20+[0.5*math.exp(0.5*(time-lagtime)) for time in time[20:]] biomass2 = [0.5*math.exp(0.5*(time)) for time in time] biomass3 = [0.5*math.exp(0.25*(time)) for time in time] temp1 = np.random.normal(size=len(time),loc=37,scale=0.5) temp2 = np.random.normal(size=len(time),loc=37,scale=0.2) fakedfferm = pd.DataFrame(data={"pH-1" : pH1, "pH-2" : pH2, "biomass-1" : biomass1, "biomass-2" : biomass2, "biomass-3" : biomass3, "temperature-1" : temp1, "temperature-2" : temp2}, columns=["pH-1", "pH-2", "biomass-1", "biomass-2", "biomass-3", "temperature-1", "temperature-2"], index=time)What our fake data looks like?
fakedfcc
num |
numpower |
|
|---|---|---|
0 |
49.5832 |
4.95832e+06 |
1 |
49.9437 |
4.99437e+06 |
2 |
47.8638 |
4.78638e+06 |
3 |
51.6403 |
5.16403e+06 |
4 |
48.2066 |
4.82066e+06 |
… |
… |
… |
fakedfferm
pH-1 |
pH-2 |
biomass-1 |
biomass-2 |
biomass-3 |
temperature-1 |
temperature-2 |
|
|---|---|---|---|---|---|---|---|
0 |
6.50581 |
7.20183 |
0.5 |
0.5 |
0.5 |
36.9201 |
36.9473 |
0.0833333 |
6.50193 |
7.20387 |
0.5 |
0.521273 |
0.510526 |
37.2745 |
36.8645 |
0.166667 |
6.49433 |
7.19818 |
0.5 |
0.543452 |
0.521273 |
36.6908 |
37.0654 |
0.25 |
6.50217 |
7.19562 |
0.5 |
0.566574 |
0.532247 |
37.1894 |
36.7089 |
0.333333 |
6.49848 |
7.20198 |
0.5 |
0.59068 |
0.543452 |
37.2566 |
36.9257 |
… |
… |
… |
… |
… |
… |
… |
… |
Demo of fermy
import fermy # Control Chart Demo fakedfcc.fccplot("num") fakedfcc.fccplot("numpower", forcepower=True) # Fermentation plot Demo fakedfferm.fplotmultiy(groupby="-") # Calculation on fermentation data biomassproxy = fakedfferm.iloc[:,2:5] # selection of biomass related columns biomassproxy.fermgrowth()Examples of Fermy outputs
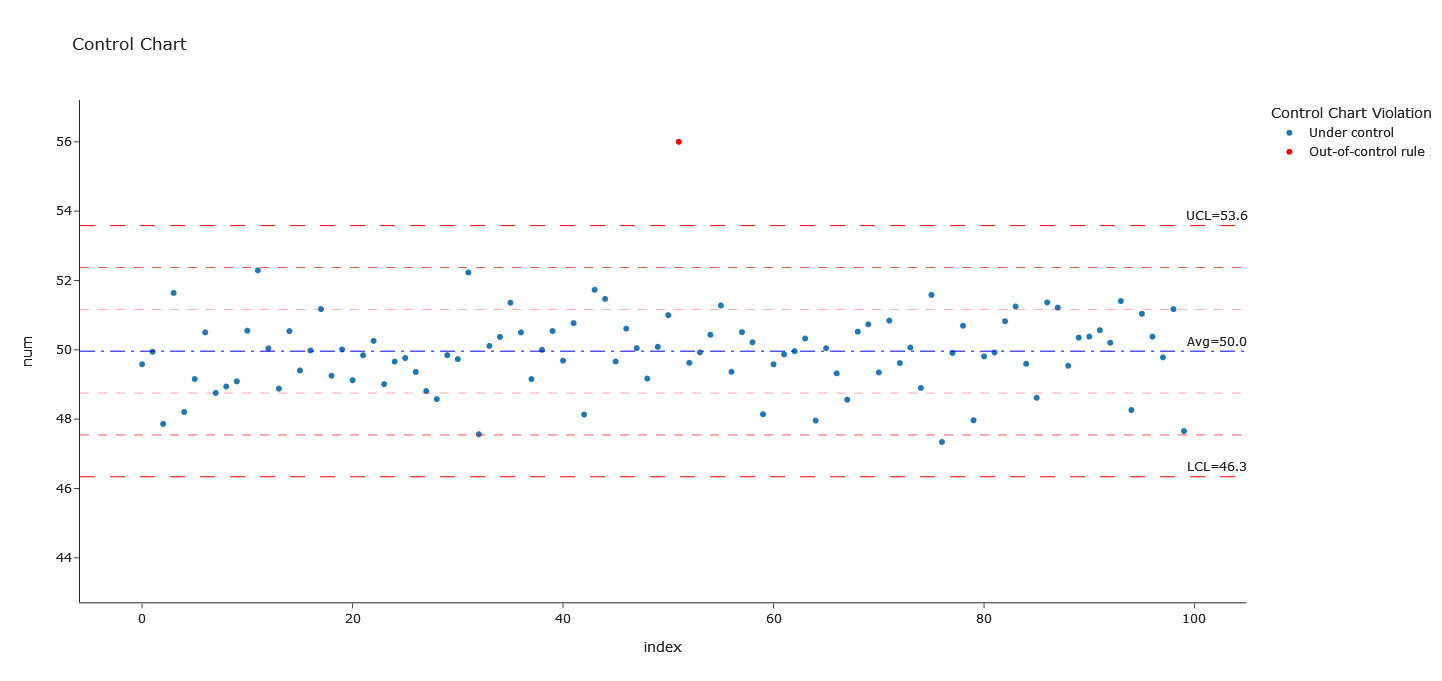
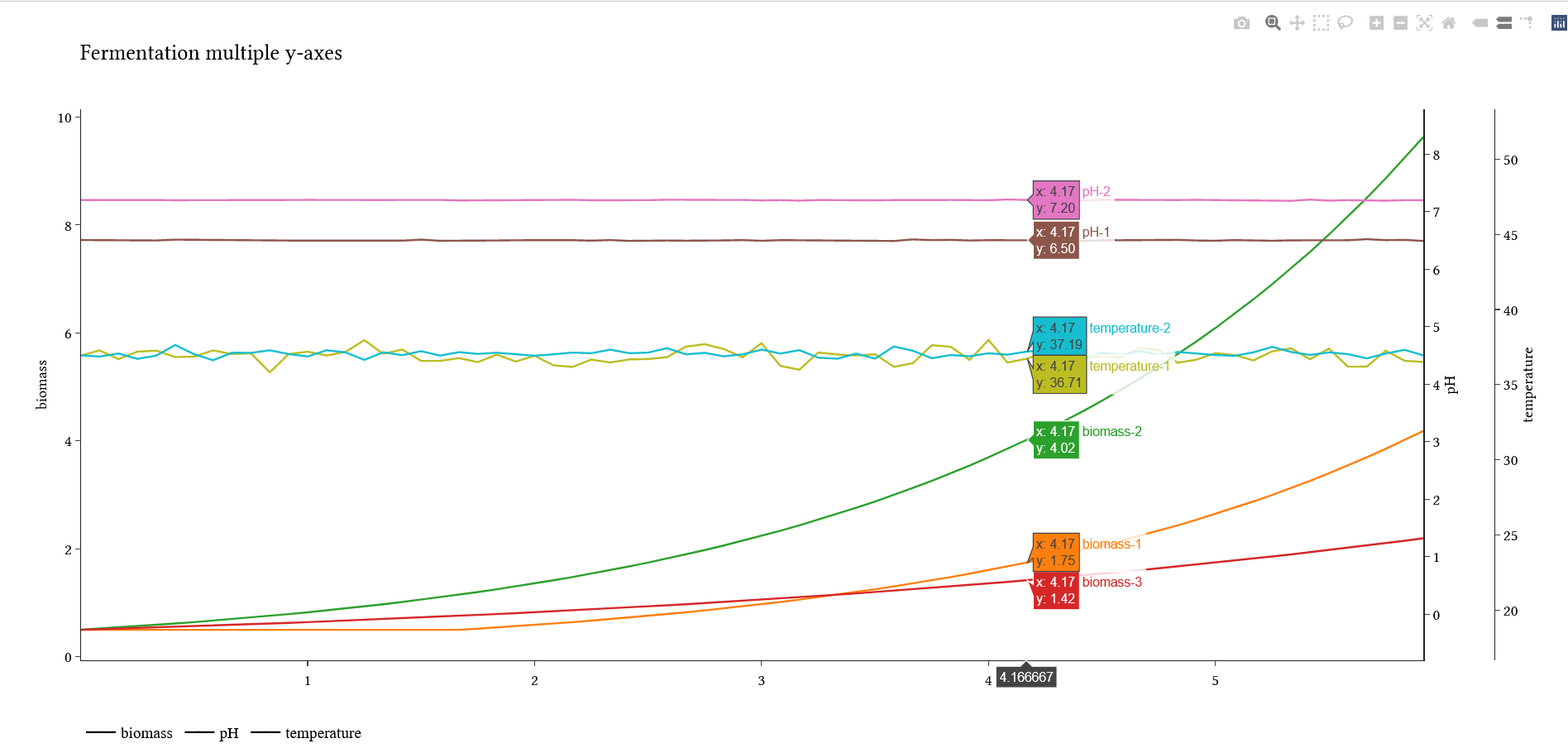
maximal_growth_rate_per_h |
lagtime_h |
maximal_growth_rate_time_h |
|
|---|---|---|---|
biomass-1 |
0.5 |
1.67 |
2.58 |
biomass-2 |
0.5 |
0.17 |
3.83 |
biomass-3 |
0.25 |
0.17 |
5.25 |
Examples of CINAC like calculations
import pandas as pd import fermy.CINAC dfcinac = pd.read_csv("https://gitlab.com/Shinuginn/data-sample/-/raw/main/pHkinetic.csv",sep=";",index_col=0) desc = dfcinac.cinac() print(dfcinac) # print dataframe with pH kinetics print(desc) # print dataframe with cinac descriptors # Way to add a new descriptor named newdescr def newdescr(seriepH:pd.Series): return seriepH.max() fermy.CINAC.mycinactable.append(newdescr) desc = dfcinac.cinac() print(desc) # print dataframe with cinac descriptors plus a new one # New descriptors can be built bases one of the four mother functions: # TimetopH(pHtarget) or pHatTime(Time) or TimeDeltapH (pHini, pHfin, taux:bool) or Ta(timepHini, deltapH) # Exemple: slope between pH 5.9 and 5 def slopebetweenpH5dot9and5(seriepH:pd.Series): return fermy.CINAC.TimeDeltapH(seriepH,5.9,5,True) fermy.CINAC.mycinactable.append(slopebetweenpH5dot9and5)Examples of MTP option
import fermy.MTP reads = fermy.MTP.MTPReader("fakepathasstring","fakeMTP") print(reads) # The MTP reader is set as fakeMTP # The path of data file is fakepathasstring # Other avaible readers ['Epoch2', 'fakeMTP', 'Tecan96', 'Tecan384', 'Logphase' ,'Fluostar'] dfMTP = reads.readMTP() print(dfMTP) # Dataframe with well coordinates as columns and Time of run float of hours as index
Growth Rate Algorithm Description
Normalization of data with two user-defined ways. First by divided all data points by a percentage (5 % percent by default) of the maximum value of the distribution. This option may be used if initial data are very noisy (e.g. Biomass proxy coming from a lab scale). Second method divide all data points by the average of the first five points (like in Toussaint et al. 2006). To be more robust regarding next steps each values under 1 is replaced by 1.
Then natural logarithm is applied to the normalized data like in Toussaint et al. 2006
A smoothing procedure is applied to the corrected biomass proxy by averaging each point with its eight closest neighbors like in Toussaint et al. 2006.
The slope of each point was obtained by calculating the slope between the two fourth neighboring points on each side like in Toussaint et al. 2006.
The exponential growth rate area (EGRA) is defined where slopes are equal to or greater than 95% of the maximum slope value like in Hall et al 2014.
Finally, linear regression is calculated in the EGRA and the slope of the regression gives the maximum (specific) growth rate and the intercept gives Lag time.
Biological signification
The maximum (specific) growth rate (commonly express in per hours) is the growth rate during logarithmic growth phase (in batch culture) corresponding to the maximum value for the specific condition.
Lag time (commonly express in hours) is the duration of the phase where growth is absent at the beginning of the culture.
Bibliography
Hall B.G., Acar H., Nandipati A. and Barlow M. Growth rates made easy. Molecular Biology and Evolution, 31 (1):232-238, 2014.
Toussaint H., Levasseur G., Gervais-Bird J.,Wellinger R. J., Elela S. A., and Conconi A. A high-throughput method to measure the sensitivity of yeast cells to genotoxic agents in liquid cultures. Mutation Research/Genetic Toxicology and Environmental Mutagenesis, 606 (1-2):92-105, jul 2006.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







