An end-to-end gpu Python library that encodes categorical variables into machine-learnable numerics

Project description
cu-cat

cu-cat is an end-to-end gpu Python library that encodes categorical variables into machine-learnable numerics. It is a cuda accelerated port of what was dirty_cat, now rebranded as skrub, and allows more ambitious interactive analysis & real-time pipelines!
What can cu-cat do?
The latest PyGraphistry[AI] release GPU accelerates to its automatic feature encoding pipeline, and to do so, we are delighted to introduce the newest member to the open source GPU dataframe ecosystem: cu_cat! The Graphistry team has been growing the library out of need. The straw that broke the camel’s back was in December 2022 when we were hacking on our winning entry to the US Cyber Command AI competition for automatically correlating & triaging gigabytes of alerts, and we realized that what was slowing down our team's iteration cycles was CPU-based feature engineering, basically pouring sand into our otherwise humming end-to-end GPU AI pipeline. Two months later, cu_cat was born. Fast forward to now, and we are getting ready to make it default-on for all our work.
Hinted by its name, cu_cat is our GPU-accelerated open source fork of the popular CPU Python library dirty_cat. Like dirty_cat, cu_cat makes it easy to convert messy dataframes filled with numbers, strings, and timestamps into numeric feature columns optimized for AI models. It adds interoperability for GPU dataframes and replaces key kernels and algorithms with faster and more scalable GPU variants. Even on low-end GPUs, we are now able to tackle much larger datasets in the same amount of time – or for the first time! – with end-to-end pipelines. We typically save time with 3-5X speedups and will even see 10X+, to the point that the more data you encode, the more time you save!
What can cu-cat NOT do?
Since cu_cat is limited to CUDF/CUML dataframes, it is not a drop-in replacement for dirty_cat. While it can also fallback to CPU, it is also not a drop-in replacement for the CPU-based dirty_cat, and we are not planning to make it one. We developed this library to accelerate our own graphistry end-to-end pipelines, and as such it is only TableVectorizer and GapEncoder which have been optimized to take advantage of a GPU speed boost.
Similarly, cu_cat requires pandas or cudf input numpy array can be featurized but cannot be UMAP-ed since they lack index, and are thus not supported.
What degree of speed boost can I expect with cu-cat, compared to dirty-cat or similar CPU feature encoders?
We have routinely experienced boosts of 2x on smaller datasets to 10x and more as one scales data into millions of features (features roughly equates to unique elements in rows x columns). One can observe this in the video above, demonstrated in the following plots:
There is an inflection point when overhead of transing data to GPU is offset by speed boost, as we can see here. The axis represent unique features being inferred.
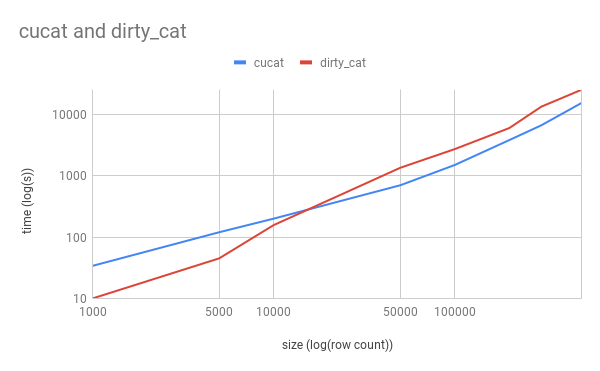
As we can see, with scale the divergence in speed is obvious.
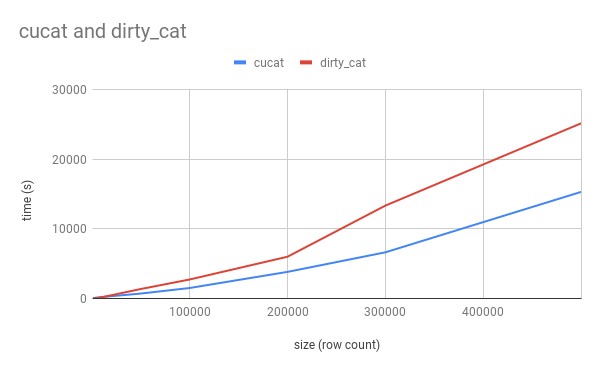
However, this graph does not mean to imply the trend goes on forever, as currently cu-cat is single GPU and cannot batch (as the transfer cost is too much for our current needs), and thus each dataset, and indeed GPU + GPU memory, is unique, and thus these plots are meant merely for demonstrative purposes. GPU = colab T4 + 15gb mem and colab CPU + 12gb memory
Startup Code demonstrating speedup:
! pip install cu-cat dirty-cat
from time import time
from cu_cat._table_vectorizer import TableVectorizer as cu_TableVectorizer
from dirty_cat._table_vectorizer import TableVectorizer as dirty_TableVectorizer
from sklearn.datasets import fetch_20newsgroups
n_samples = 2000 # speed boost improves as n_samples increases, to the limit of gpu mem
news, _ = fetch_20newsgroups(
shuffle=True,
random_state=1,
remove=("headers", "footers", "quotes"),
return_X_y=True,
)
news = news[:n_samples]
news=pd.DataFrame(news)
table_vec = cu_TableVectorizer()
t = time()
aa = table_vec.fit_transform((news))
ct = time() - t
# if deps.dirty_cat:
t = time()
bb = dirty_TableVectorizer().fit_transform(news)
dt = time() - t
print(f"cu_cat: {ct:.2f}s, dirty_cat: {dt:.2f}s, speedup: {dt/ct:.2f}x")
>>> cu_cat: 58.76s, dirty_cat: 84.54s, speedup: 1.44x
Enhanced Code using Graphistry:
# !pip install graphistry[ai] ## future releases will have this by default
!pip install git+https://github.com/graphistry/pygraphistry.git@dev/depman_gpufeat
import cudf
import graphistry
df = cudf.read_csv(...)
g = graphistry.nodes(df).featurize(feature_engine='cu_cat')
print(g._node_features.describe()) # friendly dataframe interfaces
g.umap().plot() # ML/AI embedding model using the features
Example notebooks
Hello cu-cat notebook goes in-depth on how to identify and deal with messy data using the cu-cat library.
CPU v GPU Biological Demos:
-
Single Cell analysis generically and Single Cell analysis accelerated by cu-cat
-
Chemical Mapping generically and Chemical Mapping accelerated with cu-cat
-
Metagenomic Analysis generically and Metagenomic Analysis accelerated with cu-cat
Dependencies
Major dependencies the cuml and cudf libraries, as well as standard python libraries
Related projects
dirty_cat is now rebranded as part of the sklearn family as skrub
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







