A lightweight Python library for constructing, processing, and visualizing constituent trees.

Project description
Constituent Treelib (CTL)
A lightweight Python library for constructing, processing, and visualizing constituent trees.

Description
CTL is a lightweight Python library that offers you a convenient way to parse sentences into constituent trees, modify them according to their structure, as well as visualize and export them into various file formats. In addition, you can extract phrases according to their phrasal categories (which can be used e.g., as features for various NLP tasks), validate already parsed sentences in bracket notation or convert them back into sentences.
CTL is built on top of benepar (Berkeley Neural Parser) as well as the two well-known NLP frameworks spaCy and NLTK. Here, spaCy is used for tokenization and sentence segmentation, while benepar performs the actual parsing of the sentences. NLTK, on the other hand, provides the fundamental data structure for storing and processing the parsed sentences.
To gain a clearer picture of what a constituent tree looks like, we consider the following example. Let S denote the sentence...
"Isaac Asimov was an American writer and professor of biochemistry at Boston University."
This sentence can be parsed into a bracketed tree string representation (shown below in a Penn tree-bank style)
(S
(NP (NNP Isaac) (NNP Asimov))
(VP
(VBD was)
(NP
(NP (DT an) (JJ American) (NN writer) (CC and) (NN professor))
(PP (IN of) (NP (NN biochemistry)))
(PP (IN at) (NP (NNP Boston) (NNP University)))))
(. .))
which represents the actual constituent tree. However, since this notation is not really easy to read, we can turn it into a nicer visualization using - guess what - CTL! Once we have parsed and visualized the tree, we can export it to a desired format, here for example as a PNG file:
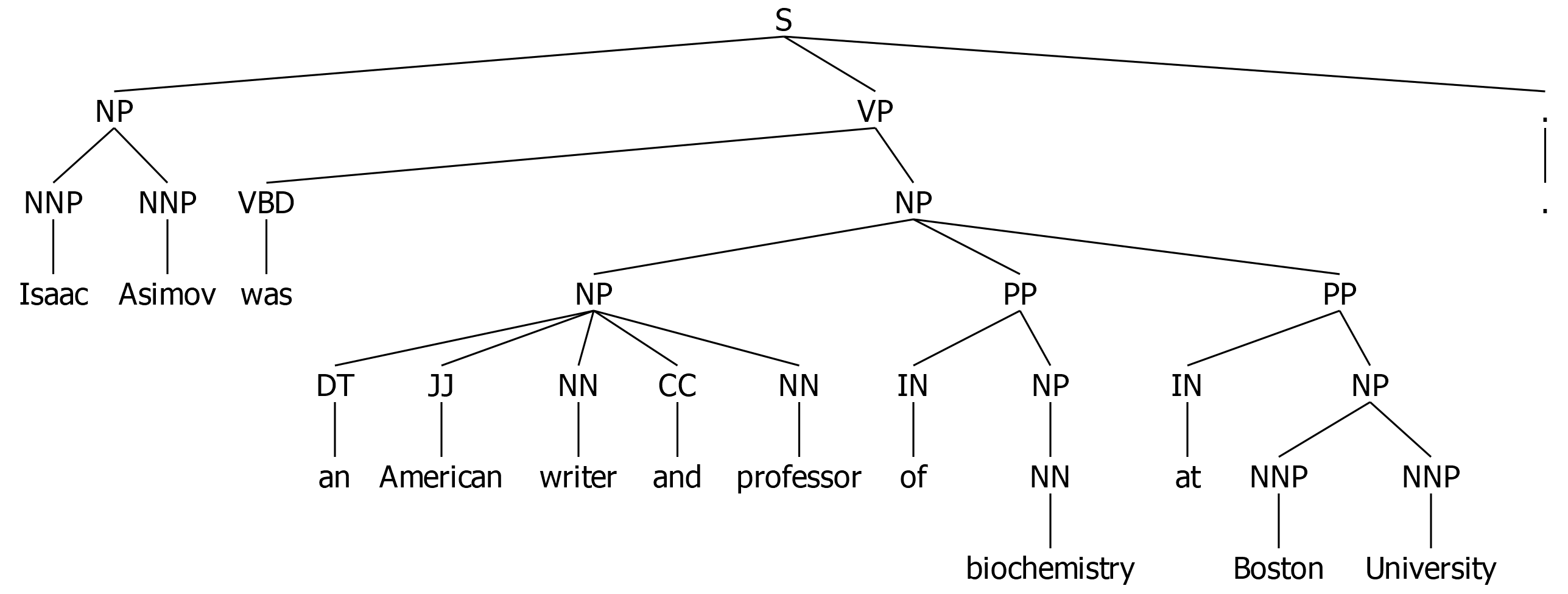
In case you grew up in the Usenet era, you might prefer the classic ASCII-ART look...
S
__________________________________|____________________________________________________________
| VP |
| _________|____________________ |
| | NP |
| | ____________|________________________________ |
| | | PP PP |
| | | ___|_______ ____|_____ |
NP | NP | NP | NP |
____|____ | _____________|____________ | | | _____|______ |
NNP NNP VBD DT JJ NN CC NN IN NN IN NNP NNP .
| | | | | | | | | | | | | |
Isaac Asimov was an American writer and professor of biochemistry at Boston University .
Regardless of which format is considered, the underlying representation[^1] shows three aspects of the structure of S:
- Linear order of the words and their part-of-speech:
NNP = Isaac,NNP = Asimov,VBD = was, ... - Groupings of the words and their part-of-speech into phrases:
NP = Isaac Asimov,VP = an American writer and professor,PP = of biochemistryandPP = at Boston University - Hierarchical structure of the phrases:
S,VP,NPandPP
Applications
Constituent trees offer a wide range of applications including:
- Analysis and comparison of sentence structures between different languages for (computational) linguists
- Extracting phrasal features for certain NLP tasks (e.g., Machine Translation, Information Extraction, Paraphrasing, Stylometry, Deception Detection or Natural Language Watermarking)
- Using the resulting representations as an input to train GNNs for specific tasks (e.g., Chemical–Drug Relation Extraction or Semantic Role Labeling)
Features
- Easy construction of constituent trees from raw or already processed sentences
- Converting parsed constituent trees back into sentences
- Convenient export of tree visualizations into various file formats
- Extraction of phrases according to their phrasal categories
- Manipulation of the tree structure (without inner postag nodes or without token leaves)
- Multilingual (currently CTL supports eight languages)
- Automatic NLP pipeline creation (loads and installs the benepar + spaCy models on demand)
- No API dependency (after downloading the models CTL can be used completely offline)
- Extensively documented source code
No Code Demo
In case you just want to play around with CTL, there is a minimally functional Streamlit app that will be gradually extended. To run the demo, please first install Streamlit via: pip install streamlit. Afterwards, you can call the app from the command line as follows: streamlit run ctl_app.py
Installation
The easiest way to install CTL is to use pip, where you can choose between (1) the PyPI[^2] repository and (2) this repository.
-
(1)
pip install constituent-treelib -
(2)
pip install git+https://github.com/Halvani/constituent_treelib.git
The latter will pull and install the latest commit from this repository as well as the required Python dependencies.
Non-Python dependencies:
CTL also relies on two open-source tools to export constituent trees into various file formats:
-
To export the constituent tree into a PDF, the command line tool wkhtmltopdf is required. Once downloaded and installed, the path to the wkhtmltopdf binary must be passed to the export function.
-
To export the constituent tree into the file formats JPG, PNG, GIF, BMP, EPS, PSD, TIFF and YAML, the software suite ImageMagick is required.
Quickstart
Below you can find several examples of the core functionality of CTL. More examples can be found in the jupyter notebook demo.
Creating an NLP pipeline
To instantiate a ConstituentTree object, CTL requires a spaCy-based NLP pipeline that incorporates a benepar component. Although you can set up this pipeline yourself, it is recommended (and more convenient) to let CTL do it for you automatically via the create_pipeline() method. Given the desired language, this method creates the NLP pipeline and also downloads[^3] the corresponding spaCy and benepar models, if requested. The following code shows an example of this:
from constituent_treelib import ConstituentTree, BracketedTree, Language, Structure
# Define the language for the sentence as well as for the spaCy and benepar models
language = Language.English
# Define which specific SpaCy model should be used (default is Medium)
spacy_model_size = ConstituentTree.SpacyModelSize.Medium
# Create the pipeline (note, the required models will be downloaded and installed automatically)
nlp = ConstituentTree.create_pipeline(language, spacy_model_size)
>>> ✔ Download and installation successful
>>> You can now load the package via spacy.load('en_core_web_md')
>>> [nltk_data] Downloading package benepar_en3 to
>>> [nltk_data] [..] \nltk_data...
>>> [nltk_data] Unzipping models\benepar_en3.zip.
Define a sentence
Next, we instantiate a ConstituentTree object and pass it the created NLP pipeline along with a sentence to parse, e.g. the memorable quote "You must construct additional pylons!"^4. Rather than a raw sentence, ConstituentTree also accepts an already parsed sentence wrapped as a BracketedTree object, or alternatively in the form of an NLTK tree. The following example illustrates all three options:
# Raw sentence
sentence = 'You must construct additional pylons!'
# Parsed sentence wrapped as a BracketedTree object
bracketed_tree_string = '(S (NP (PRP You)) (VP (MD must) (VP (VB construct) (NP (JJ additional) (NNS pylons)))) (. !))'
sentence = BracketedTree(bracketed_tree_string)
# Parsed sentence in the form of an NLTK tree
from nltk import Tree
sentence = Tree('S', [Tree('NP', [Tree('PRP', ['You'])]), Tree('VP', [Tree('MD', ['must']), Tree('VP', [Tree('VB', ['construct']), Tree('NP', [Tree('JJ', ['additional']), Tree('NNS', ['pylons'])])])]), Tree('.', ['!'])])
tree = ConstituentTree(sentence, nlp)
Modified tree structure
CTL allows you to modify the structure of the tree by either:
-
Eliminating inner postag nodes (tree contains now phrasal categories as inner nodes and tokens as leaves)
-
Eliminating token leaves (tree contains now phrasal categories as inner nodes and postags as leaves)
without_token_leaves = ConstituentTree(sentence, nlp, Structure.WithoutTokenLeaves)
without_inner_postag_nodes = ConstituentTree(sentence, nlp, Structure.WithoutPostagNodes)
The result...

Modified tree structures offer several benefits. One of them, for example, is saving space when using the visualizations in papers. Eliminating the inner postag nodes (shown on the right) reduces the tree height from level 5 to 4. Another useful application arises from the elimination of token leaves, which will be discussed in more detail in the following section.
Extract phrases
Once we have created tree, we can now extract phrases according to given phrasal categories e.g., verb phrases:
phrases = tree.extract_all_phrases()
print(phrases)
>>> {'S': ['You must construct additional pylons !'],
>>> 'VP': ['must construct additional pylons', 'construct additional pylons'],
>>> 'NP': ['additional pylons']}
# Only verb phrases..
print(phrases['VP'])
>>> ['must construct additional pylons', 'construct additional pylons']
As can be seen here, the second verb phrase is contained in the former. To avoid this, we can instruct the method to disregard nested phrases:
non_nested_phrases = tree.extract_all_phrases(avoid_nested_phrases=True)
print(non_nested_phrases['VP'])
>>> ['must construct additional pylons']
If you want to extract phrases, but are more interested in their postag representation than the actual words/tokens, you can apply the same function to the modified tree...
pos_phrases = without_token_leaves.extract_all_phrases()
print(pos_phrases)
>>> {'S': ['PRP MD VB JJ NNS .'],
>>> 'NP': ['JJ NNS'],
>>> 'VP': ['MD VB JJ NNS', 'VB JJ NNS']}
This is especially helpful when investigating the writing style of authors.
Export the tree
CTL offers you to export a constituent tree into various file formats, which are listed below. Most of these formats result in a visualization of the tree, while the remaining file formats are used for data exchange.
| Extension | Description | Output |
|---|---|---|
| Portable Document Format | Vector graphic | |
| SVG | Scalable Vector Graphics | Vector graphic |
| EPS | Encapsulated PostScript | Vector graphic |
| JPG | Joint Photographic Experts Group | Raster image |
| PNG | Portable Network Graphics | Raster image |
| GIF | Graphics Interchange Format | Raster image |
| BMP | Bitmap | Raster image |
| PSD | Photoshop Document | Raster image |
| TIFF | Tagged Image File Format | Raster image |
| JSON | JavaScript Object Notation | Data exchange format |
| YAML | Yet Another Markup Language | Data exchange format |
| TXT | Plain-Text | Pretty-print text visualization |
| TEX | LaTeX-Document | LaTeX-typesetting |
The following example shows an export of the tree into a PDF file:
tree.export_tree(destination_filepath='my_tree.pdf', verbose=True)
>>> PDF - file successfully saved to: my_tree.pdf
In the case of raster/vector images, CTL automatically removes unnecessary margins with respect to the resulting visualizations. This is particularly useful if the visualizations are to be used in papers.
Available models and languages
CTL currently supports eight languages: English, German, French, Polish, Hungarian, Swedish, Chinese and Korean. The performance of the respective models can be looked up in the benepar repository.
License
The code and the jupyter notebook demo of CTL are released under the MIT License. See LICENSE for further details.
Citation
If you find this repository helpful, feel free to cite it in your paper or project:
@software{Halvani_Constituent_Treelib_-_2023,
author = {Halvani, Oren},
doi = {10.5281/zenodo.7765147},
month = {3},
title = {{Constituent Treelib - A Lightweight Python Library for Constructing, Processing, and Visualizing Constituent Trees.}},
url = {https://github.com/Halvani/constituent-treelib},
version = {0.0.6},
year = {2023
}
Please also give credit to the authors of benepar and cite their work.
[^1]: Note, if you are not familiar with the bracket labels of constituent trees, have a look at the following Gist or alternatively this website.
[^2]: It's recommended to install CTL from PyPI (Python Package Index). However, if you want to benefit from the latest update of CTL, you should use this repository instead, since I will only update PyPi at irregular intervals.
[^3]: After the models have been downloaded, they are cached so that there are no redundant downloads when the method is called again. However, loading and initializing the spaCy and benepar models can take a while, so it makes sense to invoke the create_pipeline() method only once if you want to process multiple sentences.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for constituent_treelib-0.0.7.tar.gz
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 2b60e329b297219682f097782044a9e0620ece83cba24231aaef6c5c72dfefca |
|
| MD5 | 45ef0ae20b70ea9711d94c5a1f2160ac |
|
| BLAKE2b-256 | bd06a872cfbe56d8b202ea1089ce115362e3efc5adf0291e28024cc978b5589a |
Hashes for constituent_treelib-0.0.7-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 6b9332026dc7b86f1575cce4b4386777fe4fc249c7d18d792826c4203b664b7e |
|
| MD5 | ec479be18f4121c6e0b75b0f8065d64a |
|
| BLAKE2b-256 | 3c3a7a11fe50cc571cdffb4631c839b7c1883fd6d02f4f120fb9fe452d16cf5e |








{kind=link}